Image Processing

DRIVE Dataset: The DRIVE dataset consists of 40 fundus images collected from 7 patients with retinal disease and 33 healthy individuals. Each image has a resolution of 584 × 565 pixels. A total of 20 images are used for training, while the remaining 20 images are designated for testing. Each image has two annotations provided by two different experts, and we use the first annotation as the ground truth.
- Categories:
 2 Views
2 Views
DRIVE Dataset: The DRIVE dataset consists of 40 fundus images collected from 7 patients with retinal disease and 33 healthy individuals. Each image has a resolution of 584 × 565 pixels. A total of 20 images are used for training, while the remaining 20 images are designated for testing. Each image has two annotations provided by two different experts, and we use the first annotation as the ground truth.
- Categories:
1 Views
The CSV data files in the ZIP archive are analytical datasets extracted and processed from the RUG-EGO-FALL dataset, intended to support fall detection research using wearable first-person perspective devices. The data includes visual motion information for each video frame, calculated using the ORB (Oriented FAST and Rotated BRIEF) feature point algorithm in combination with the Lucas-Kanade optical flow method.
- Categories:
22 Views
This paper proposed a PE-VAE-GAN network that adaptively selected image reconstruction networks based on flow pattern classification, significantly improving the quality of Electrical Resistance Tomography (ERT) reconstructed images.To address insufficient feature extraction from voltage data,we presented a pseudo-image encoding method that converted the one-dimensional voltage signals into the two-dimensional grayscale images.
- Categories:
11 Views
The ORSSD dataset consists of 800 optical remote sensing images with corresponding pixel-level annotations, divided into a training set of 600 images and a test set of 200 images. The EORSSD dataset is an extension of ORSSD, adding 1200 ORSIs for a total of 2000 images, and is split into 1400 training images and 600 test images.
- Categories:
22 Views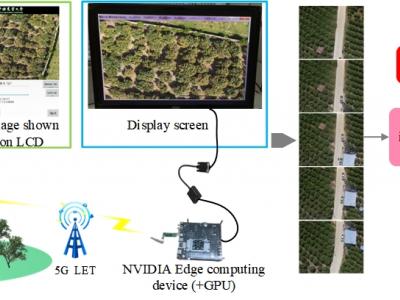
The system consists of an UAVs remote sensing system and an edge computing system. The core components of the UAVs remote sensing system mainly consist of the imaging system K510 development board and a 5G module. The K510 comes equipped with a camera and an LCD screen. The edge computing system constructed in this paper utilizes the NVIDIA Jetson series development kit, which comes with a GPU module to enhance digital image processing capabilities. The captured raw images are stitched and displayed on the NVIDIA Jetson edge computing platform using our designed improved SFIT algorithm.
- Categories:
26 Views
This dataset aims to support research on temporal segmentation of the Timed Up and Go (TUG) test using a first-person wearable camera. The data collection includes a training set of 8 participants and a test set of 60 participants. Among the 8 participants, the test was completed at both a normal walking pace and a simulated slower walking pace to mimic elderly movement patterns. The 60 participants were randomly divided into two groups: one group completed the test at a normal walking pace, and the other group simulated slower walking speed to mimic elderly movement patterns.
- Categories:
45 Views
Digital microfluidics are a unique technique for operation of nano-to-micro liter droplets based on electrowetting on dielectric. It has great application potential in the field on clinic diagnosis, life science and environment monitoring. Due to the fast droplet moving speed and high degree of freedom for droplet manipulation, it is urgent to develop automated and intelligent approaches for droplet monitoring and control.
- Categories:
38 Views
This study utilizes the open-source datasets FAIR1M and HRSC2016 as foundational resources to construct an optical remote sensing image dataset for rotated ship target detection. The dataset encompasses nine ship categories: Dry-Cargo-Ship, Engineering-Ship, Fishing-Boat, Motorboat, Tugboat, Passenger-Ship, Warship, Liquid-Cargo-Ship, and Other-Ship.
- Categories:
26 Views
Attached Image data set from combined OCT-SLO is used to train AI models and identify features to maximize quality of data set to adjust MZI reference arm, PMT Voltage of Liquid Lens and location of object. Why adjustment is needed is explained below:
- Categories:
159 Views